以前,我们试图通过无休止地堆砌和调优“提示词(Prompt Engineering)”,来约束和掌控 AI 的行为边界。然而,这种“把所有规则塞进同一个大喇叭里”的粗暴做法,很快就遇上了两大瓶颈:
上下文污染(Context Pollution)带来的“指令失焦”。 为了防范各种极端的边界 Case,开发者的 System Prompt 动辄膨胀到数万 Token。结果大模型的注意力被严重稀释,常常顾此失彼,出现严重的“指令漂移”甚至幻觉。
业务资产被“死锁”,复用成本极高。 那些耗费大量精力打磨的复杂业务逻辑,被死死地硬编码在了特定的代码仓库或对话记录中。跨项目迁移、跨团队共享几乎是不可能完成的任务。
Agent Skill 是 Anthropic 于 2025 年确立的开放式 AI 代理构建标准。其本质是将复杂的 Prompt 工程、外部知识库(Reference)与执行逻辑(Script)封装为标准化的本地文件结构(通常以 SKILL.md 为核心)。
它的核心技术突破在于渐进式披露(Progressive Disclosure)架构:模型不再需要一次性读取所有背景设定,而是仅在推理过程中,根据当前任务的意图动态挂载必要的规则片段或数据引用。
一、核心机制:渐进式披露 (Progressive Disclosure)
Agent Skill 解决上下文爆炸的核心武器是**“懒加载”**。它一改以往“全盘灌输”的做法,将技能的加载与调用分为三个精密分层的级别(L1-L3):
L1 元数据(常驻内存): Agent 初始化时,上下文中只注入所有可用技能的 Name 和 Description(通常在解析时转为 JSON Schema)。这极其节省 Token,就像给了 Agent 一本只有标题和摘要的“技能目录”。
L2 专家指令(按需加载): 当 Agent 遇到具体问题,决定触发某个 Skill 时,系统才会拦截请求,并将该技能的完整 SKILL.md(长篇 SOP 指令)注入到当前上下文中。Agent 读完后立刻按步骤执行。
L3 外部资源(执行时加载): 在执行 SOP 的过程中,Skill 还可以指导 Agent 去读取特定的外部知识库(Reference),或调用底层的物理脚本(Script),实现深度的工具隔离。
二、 Agent Skill 的标准目录结构与实战
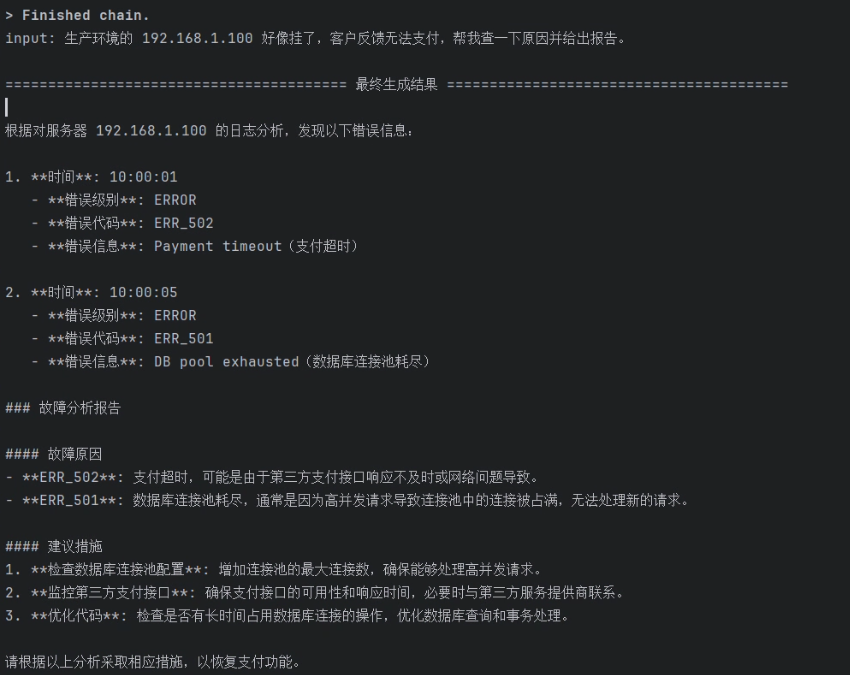
在工程落地上,一个高度可移植的 Agent Skill 通常是一个自包含的文件夹。以一个**“日志异常分析 (log_analysis)”**技能为例,它的标准目录结构如下:
1 | log_analysis/ |
其中,最核心的 SKILL.md 文件通常由两部分组成:顶部的 YAML Frontmatter(元数据)和下方的 Markdown 正文(SOP 指令)。
1 | --- |
结果展示: