时间:2025.10.25 分享人:赵文琦
1 理论体系背景
1.1 问题域
问题:有了LLMs,为什么需要开发大模型应用?
在大语言模型(LLM)如 ChatGPT、Claude、DeepSeek 等快速发展的今天,开发者不仅希望能“使用”这些模型,还希望能将它们灵活集成到自己的应用中,实现更强大的对话能力、检索增强生成 (RAG)、工具调用(Tool Calling)、多轮推理等功能。

2.大模型应用开发
大模型应用技术特点:门槛低,天花板高。
2.1 基于RAG架构的开发
背景:
- 大模型的知识冻结
- 大模型幻觉
而RAG就可以非常精准的解决这两个问题。
举例:
LLM在考试的时候面对陌生的领域,答复能力有限,然后就准备放飞自我了。而此时RAG给了一些提示和思路,让LLM懂了开始往这个提示的方向做,最终考试的正确率从60%到了90%!
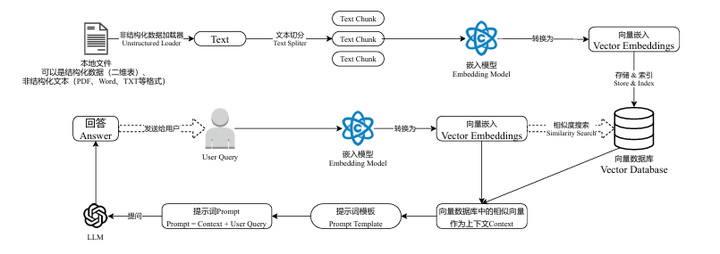
何为RAG?
Retrieval-Augmented Generation(检索增强生成)
第一阶段:知识库构建(1 -> 6)
第二阶段:问答(7 -> 15)

检索-增强-生成过程:检索可以理解为第10步,增强理解为第12步(这里的提示词包含检索到的数据),生成理解为第15步。
类似的细节图:
RAG的优缺点
RAG的优点
- 相比提示词工程,RAG有更丰富的上下文和数据样本,可以不需要用户提供过多的背景描述,就能生成比较符合用户预期的答案。
- 相比于模型微调,RAG可以提升问答内容的时效性和可靠性
- 在一定程度上保护了数据的隐私性。
RAG的缺点
- 由于每次问答都涉及外部系统数据检索,因此RAG的响应时延相对较高。
- 引用的外部知识数据会消耗大量的模型Token资源。
2.2 基于Agent架构的开发
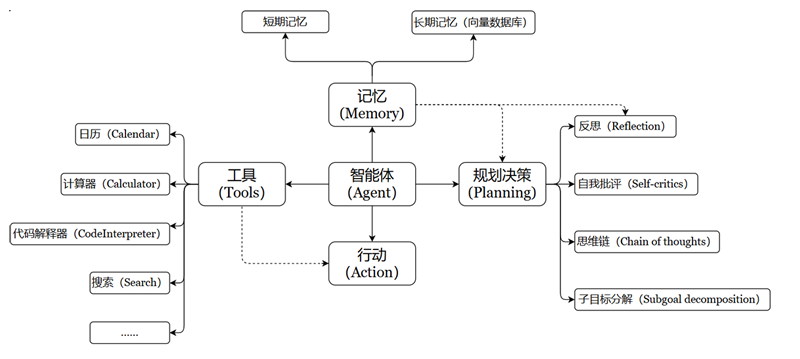
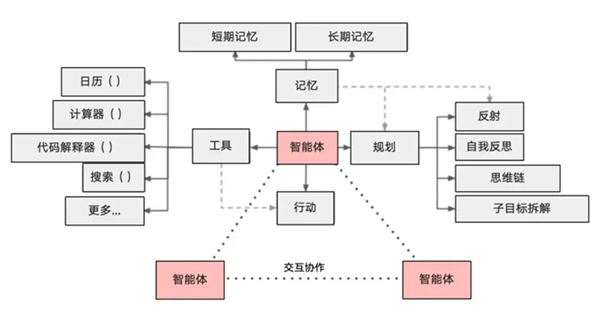
充分利用 LLM 的推理决策能力,通过增加规划、记忆和工具调用的能力,构造一个能够独立思考、逐步完成给定目标的智能体。
Agent = LLM + Memory + Tools + Planning + Action
智能体核心要素被细化为以下模块:
1、大模型(LLM)作为“大脑”:提供推理、规划和知识理解能力,是AI Agent的决策中枢。
2、记忆(Memory): 记忆机制能让智能体在处理重复⼯作时调⽤以前的经验,从而避免⽤⼾进⾏⼤量重复交互。
- 短期记忆:存储单次对话周期的上下文信息,属于临时信息存储机制。受限于模型的上下文窗口长度。
- 长期记忆:可以横跨多个任务或时间周期,可存储并调用核心知识,非即时任务。 长期记忆,可以通过模型参数微调(固化知识)、知识图谱(结构化语义网络)或向量数据库 (相似性检索)方式实现。
3、工具使用(Tool Use):调用外部工具(如API、数据库)扩展能力边界。
4、规划决策(Planning):通过任务分解、反思与自省框架实现复杂任务处理。例如,利用思维链 (Chain of Thought)将目标拆解为子任务,并通过反馈优化策略。
5、行动(Action):实际执行决策的模块,涵盖软件接口操作(如自动订票)和物理交互(如机器人 执行搬运)。比如:检索、推理、编程等
3.大模型应用开发框架——LangChain
3.1 介绍是LangChain
LangChain是 2022年10月 ,由哈佛大学的 Harrison Chase (哈里森·蔡斯)发起研发的一个开源框架, 用于开发由大语言模型(LLMs)驱动的应用程序。
比如,搭建“智能体”(Agent)、问答系统(QA)、对话机器人、文档搜索系统、企业私有知识库等.
截止到2025年7月26日,GitHub统计数据:
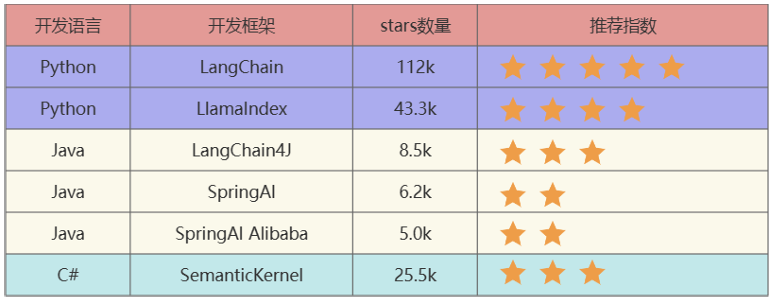
LangChain:这些工具里出现最早、最成熟的,适合复杂任务分解和单智能体应用 。LlamaIndex:专注于高效的索引和检索,适合 RAG 场景。LangChain4J:LangChain还出了Java、JavaScript(LangChain.js)两个语言的版本,LangChain4j的功能略少于LangChain,但是主要的核心功能都是有的。SpringAI/SpringAI Alibaba:有待进一步成熟,此外只是简单的对于一些接口进行了封装。SemanticKernel:也称为sk,微软推出的。
3.2 LangChain的核心组件
3.2.1 Model I/O
Model I/O 模块是与语言模型(LLMs)进行交互的核心组件,包括输入提示(Format)、调用模型(Predict)、输出解析(Parse)。
调用模型:
可以调用第三方平台模型或本地部署大模型
模型功能分类:
非对话模型(LLMs、Text Model)
对话模型(Chat Models)
嵌入模型(Embedding Models)
Prompt Template提示词模板
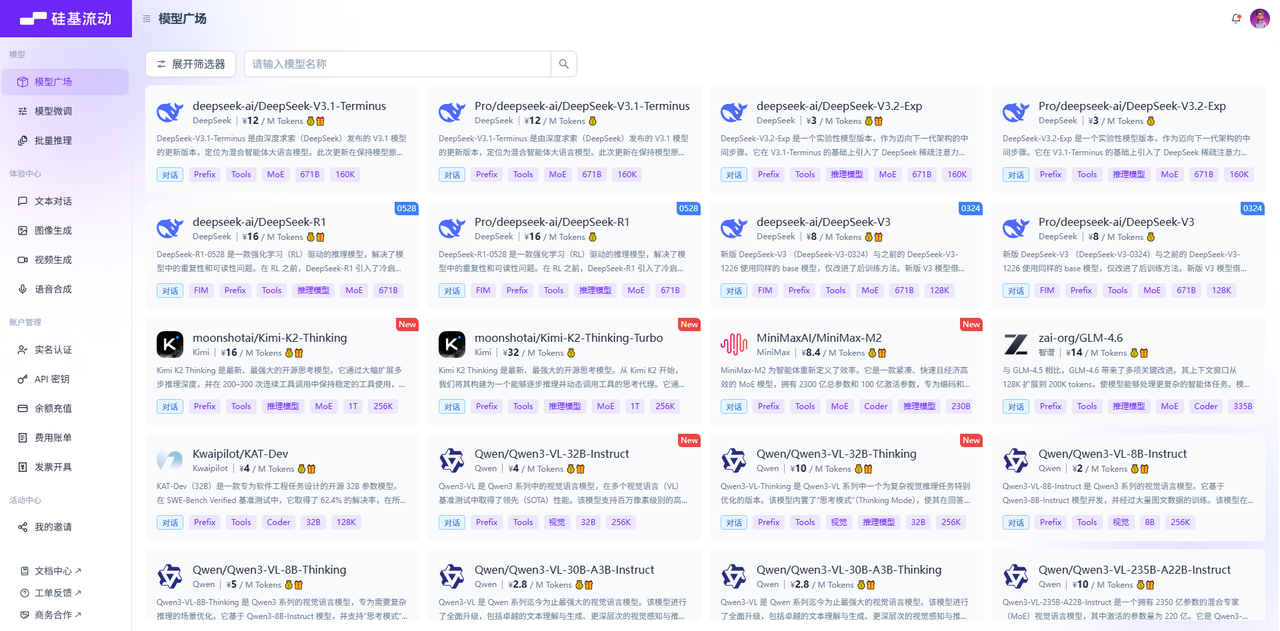
有几种不同类型的提示模板:
PromptTemplate:LLM提示模板,用于生成字符串提示。它使用 Python 的字符串来模板提示。ChatPromptTemplate:聊天提示模板,用于组合各种角色的消息模板,传入聊天模型。XxxMessagePromptTemplate:消息模板词模板,包括:SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate、 ChatMessagePromptTemplate等FewShotPromptTemplate:样本提示词模板,通过示例来教模型如何回答PipelinePrompt:管道提示词模板,用于把几个提示词组合在一起使用。自定义模板:允许基于其它模板类来定制自己的提示词模板。
Output Parsers输出解析器
LangChain有许多不同类型的输出解析器 :
StrOutputParser:字符串解析器JsonOutputParser:JSON解析器,确保输出符合特定JSON对象格式XMLOutputParser:XML解析器,允许以流行的XML格式从LLM获取结果CommaSeparatedListOutputParser:CSV解析器,模型的输出以逗号分隔,以列表形式返回输出DatetimeOutputParser:日期时间解析器,可用于将 LLM 输出解析为日期时间格式
3.2.2 Chains
基本概念:
Chain:链,用于将多个组件(提示模板、LLM模型、记忆、工具等)连接起来,形成可复用的流,完成复杂的任务。
Chain 的核心思想是通过组合不同的模块化单元,实现比单一组件更强大的功能。比如:
将LLM与 Prompt Template (提示模板)结合
将LLM与 输出解析器结合
将LLM与 外部数据结合,例如用于问答
将LLM与 长期记忆结合,例如用于聊天历史记录
通过将第一个LLM的输出作为第二个LLM 的输入,…,将多个LLM按顺序结合在一起
3.2.3 Memory
为什么需要Memory?
模型本身是不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。
如何实现记忆功能?
实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出最终结果。 而在LangChain中,提供这个功能的模块就称为Memory(记忆) ,用于存储用户和模型交互的历史信息。
Memory的设计理念
Memory,是LangChain中用于多轮对话中保存和管理上下文信息(比如文本、图像、音频等)的组 件。它让应用能够记住用户之前说了什么,从而实现对话的 感知的链式对话系统提供了基础。
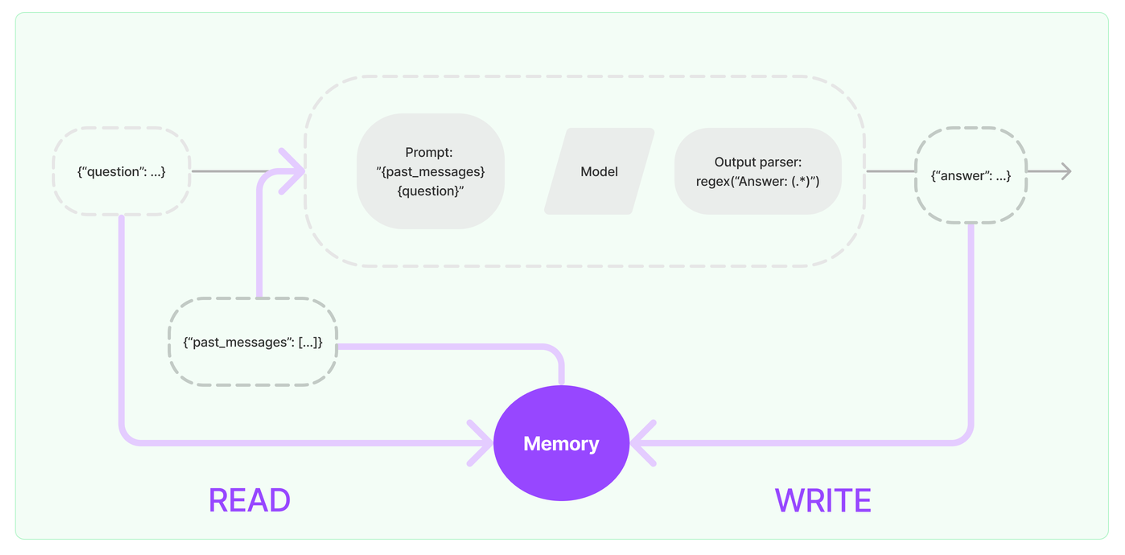
- 输入问题:({“question”: …})
- 读取历史消息:从Memory中READ历史消息({“past_messages”: […]})
- 构建提示(Prompt):读取到的历史消息和当前问题会被合并,构建一个新的Prompt
- 模型处理:构建好的提示会被传递给语言模型进行处理。语言模型根据提示生成一个输出。
- 解析输出:输出解析器通过正则表达式 regex(“Answer: (.*)”)来解析,返回一个回答({“answer”: …})给用户
- 得到回复并写入Memory:新生成的回答会与当前的问题一起写入Memory,更新对话历史。 Memory会存储最新的对话内容,为后续的对话提供上下文支持。
Memory模块的设计思路:
层次1(最直接的方式):保留一个聊天消息列表
层次2(简单的新思路):只返回最近交互的k条消息
层次3(稍微复杂一点):返回过去k条消息的简洁摘要
层次4(更复杂):从存储的消息中提取实体,并且仅返回有关当前运行中引用的实体的信息
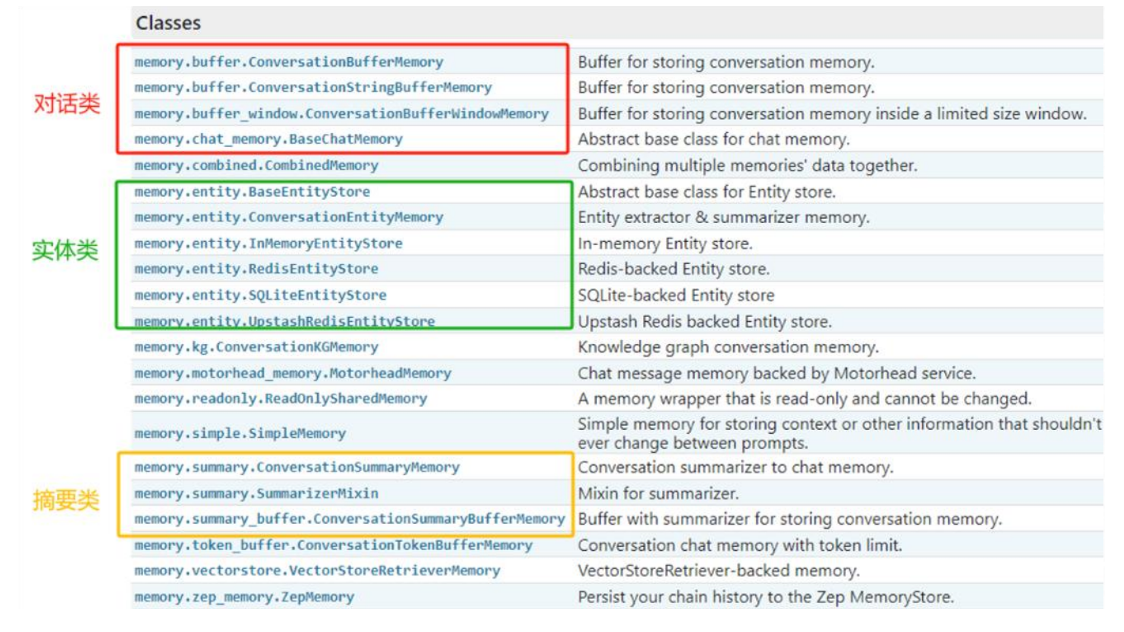
针对上述情况,LangChain构建了一些可以直接使用的 Memory工具,用于存储聊天消息的一系列集成。
3.2.4 Tools
Tools 用于扩展大语言模型(LLM)的能力,使其能够与外部系统、API 或自定义函数交互,从而完成仅靠文本生成无法实现的任务(如搜索、计算、数据库查询等)。
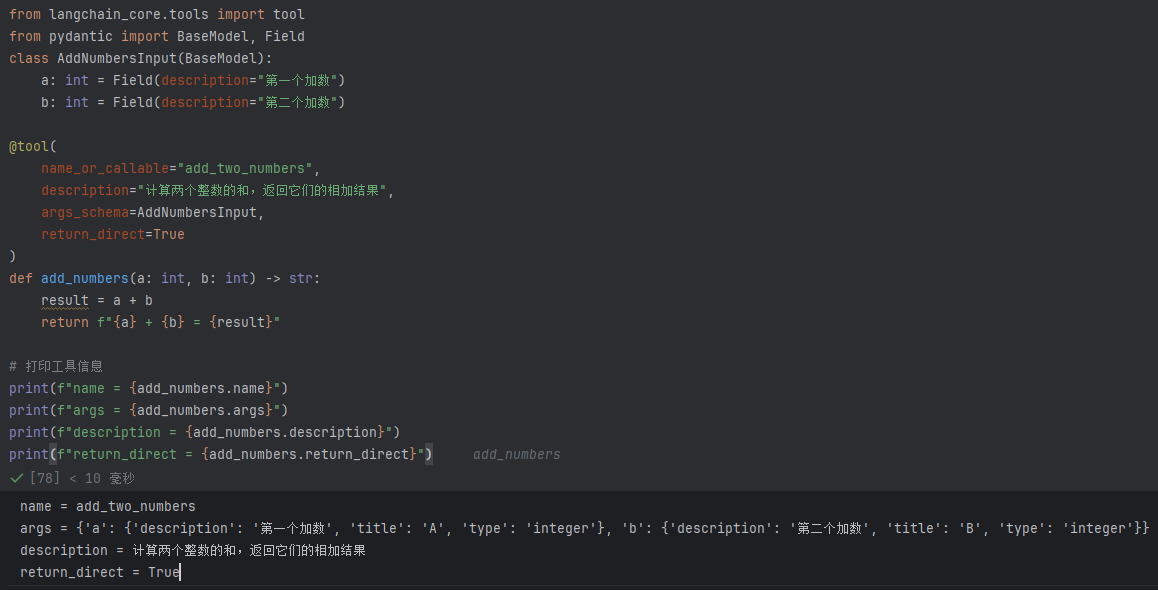
Tool 的要素:
- name :工具的名称
- description :工具的功能描述
- 该工具输入的 JSON模式
- 要调用的函数
- return_direct :是否应将工具结果直接返回给用户(仅对Agent相关)
实操步骤:
步骤1:将name、description 和 JSON模式作为上下文提供给LLM
步骤2:LLM会根据提示词推断出需要调用哪些工具,并提供具体的调用参数信息
步骤3:用户需要根据返回的工具调用信息,自行触发相关工具的回调
调用工具说明
情况1:大模型决定调用工具
如果模型认为需要调用工具(如 MoveFileTool ),返回的 message 会包含:
- content : 通常为空(因为模型选择调用工具,而非生成自然语言回复)。
- additional_kwargs : 包含工具调用的详细信息
情况2:大模型不调用工具
- 如果模型认为无需调用工具(例如用户输入与工具无关),返回的会是普通文本回复
3.2.5 Agents
通用人工智能(AGI)将是AI的终极形态,几乎已成为业界共识。同样,构建智能体(Agent)则是AI工程应用当下的“终极形态”。
(1)什么是Agent?
Agent(智能体) 是一个通过动态协调大语言模型(LLM)和工具(Tools) 来完成复杂任务的智能系统。它让LLM充当”决策大脑”,根据用户输入自主选择和执行工具(如搜索、计算、数据库查询等), 最终生成精准的响应。
(2)Agent、AgentExecutor的创建:
| 环节1:创建Agent | 环节2:创建 AgentExecutor | |
|---|---|---|
| 方式1: | 使用 AgentType 指定 | initialize_agent() |
| 方式2:(更通用) | create_xxx_agent() 比如:create_react_agent()、create_tool_calling_agent() | 调用AgentExecutor() 构造方法 |
(3)Agent的类型:
FUNCATION_CALL模式
- 基于结构化函数调用(如 OpenAI Function Calling)
- 直接生成工具调用参数( JSON 格式 ) 效率更高,
- 适合工具明确的场景
ReAct 模式
- 基于 文本推理 的链式思考(Reasoning + Acting),具备反思和自我纠错能力。
- 推理(Reasoning):分析当前状态,决定下一步行动
- 行动(Acting):调用工具并返回结果
- 通过自然语言描述决策过程
- 适合需要明确推理步骤的场景。例如智能客服、问答系统、任务执行等。
| 特性 | Function Call模式 | ReAct 模式 |
|---|---|---|
| 底层机制 | 结构化函数调用 | 自然语言推理 |
| 输出格式 | JSON/结构化数据 | 自由文本 |
| 适合场景 | 需要高效工具调用 | 需要解释决策过程 |
| 延迟 | 较低(直接参数化调用) | 较高(需生成完整文本) |
3.2.6 Retrieval
(1)Retrieval模块的设计意义
- 大模型的幻觉问题:在专有领域,LLM无法学习到所有的专业知识细节,因此在 面向专业领域知识的提问时,无法给出 可靠准确的回答,甚至会“胡言乱语”,这种现象称之为 LLM的“幻觉”。
- RAG的解决方案:当应用需求集中在利用大模型去 回答特定私有领域的知识,且知识库足够大,那么除了 型外, RAG 就是非常有效的一种缓解大模型推理的“幻觉”问题的解决方案。Retrieval对这一流程提供了解决方案。
(2)Retrieval流程
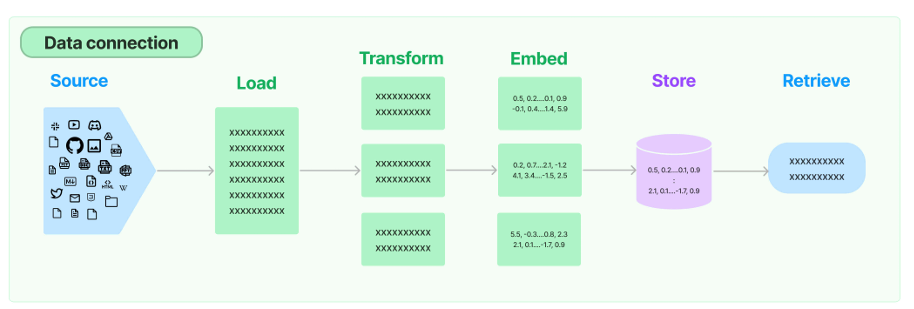
环节1:Source(数据源)
指的是RAG架构中所外挂的知识库。这里有三点说明:
- 原始数据源类型多样:如:视频、图片、文本、代码、文档等
- 形式的多样性:
- 可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件
- 可以是某一个业务流程外放的API,可以是某个网站的实时数据等
环节2:Load(加载)
环节3:Transform(转换)
Text Splitting(文档拆分)
拆分/分块的必要性:前一个环节加载后的文档对象可以直接传入文档拆分器进行拆分,而文档切块后才能向量化并存入数据库中文档拆分器的多样性:LangChain提供了丰富的文档拆分器,不仅能够切分普通文本,还能切分 Markdown、JSON、HTML、代码等特殊格式的文本。拆分/分块的挑战性:实际拆分操作中需要处理许多细节问题, 不同类型的文本、 不同的使用场景都,需要采用不同的分块策略。- 可以按照数据类型进行切片处理,比如针对文本类数据,可以直接按照字符、段落进行切片;代码类数据则需要进一步细分以保证代码的功能性;
- 可以直接根据 token 进行切片处理
在构建RAG应用程序的整个流程中,拆分/分块是最具挑战性的环节之一,它显著影响检索效果。目前还没有通用的方法可以明确指出哪一种分块策略最为有效。不同的使用场景和数据类型都会影响分块策略的选择。
环节4:Embed(嵌入)
文档嵌入模型(Text Embedding Models)负责将文本转换为向量表示,即模型赋予了文本计算机可理解的数值表示
环节5:Store(存储)
环节6:Retrieve(检索)
2 相关技术体系
低代码平台
Dify:
Dify是一个开源的大语言模型(LLM)应用开发平台,旨在简化和加速生成式AI应用的创建和部署。该平台结合了后端即服务(Backend as Service, BaaS)和LLMOps的理念,为开发者提供了一个用户友好的界面和一系列强大的工具 ,使他们能够快速搭建生产级的AI应用。
| 特性维度 | LangChain | Dify (代表低代码平台) |
|---|---|---|
| 核心定位 | 开发框架 | AI应用平台 |
| 灵活性 & 控制力 | 极高。可以自定义每一个环节,集成任何库,实现极其复杂和特定的逻辑。 | 受限。受限于平台提供的组件和功能,对于平台未支持的场景难以实现。 |
| 学习曲线 | 陡峭。需要具备编程能力,并理解LangChain的核心概念(Chain, Agent, Tool, Memory等)。 | 平缓。对非技术人员友好,只需理解AI应用的基本概念即可上手。 |
| 开发速度 | 较慢。从零开始构建,需要编写、测试和调试代码。 | 极快。通过可视化工作流和预置模板,几分钟到几小时就能搭建一个可用的应用。 |
| 部署与运维 | 自行负责。需要自己搭建服务器、配置环境、处理监控和扩展。 | 平台托管。提供一键部署、监控、日志分析、版本管理等生产级功能。 |
| 适用场景 | 1.研究和实验新的AI应用范式。 2. 构建高度定制化、复杂的企业级系统。 3. 需要与特定或老旧系统深度集成。 4. 开发全新的Agent或Chain逻辑。 | 1.快速构建MVP或内部工具。 2. 让产品经理、运营人员等非技术人员也能创建AI应用。 3. 构建标准的聊天机器人、知识库问答、文本生成等应用。 4. 追求快速上线和迭代 |
如何选择?
选择 LangChain 当:
- 你是开发者或技术团队,并且希望拥有对应用的完全控制权。
- 你的需求非常独特或复杂,超出了低代码平台的能力范围(例如,需要设计一个具有复杂推理步骤的自主Agent)。
- 你需要将AI能力深度集成到已有的复杂代码库或架构中。
- 你正在探索AI应用的边界,而不仅仅是使用现成的模式。
选择 Dify 等低代码平台当:
- 你希望快速验证一个想法,构建一个可用的原型或最小可行产品。
- 你的团队中缺乏强大的开发资源,或者希望让业务人员直接参与应用创建。
- 你的应用场景是常见且标准的(如基于文档的问答、内容摘要、简单聊天机器人)。
- 你不想操心基础设施、部署和运维的麻烦,希望开箱即用。
3 应用场景
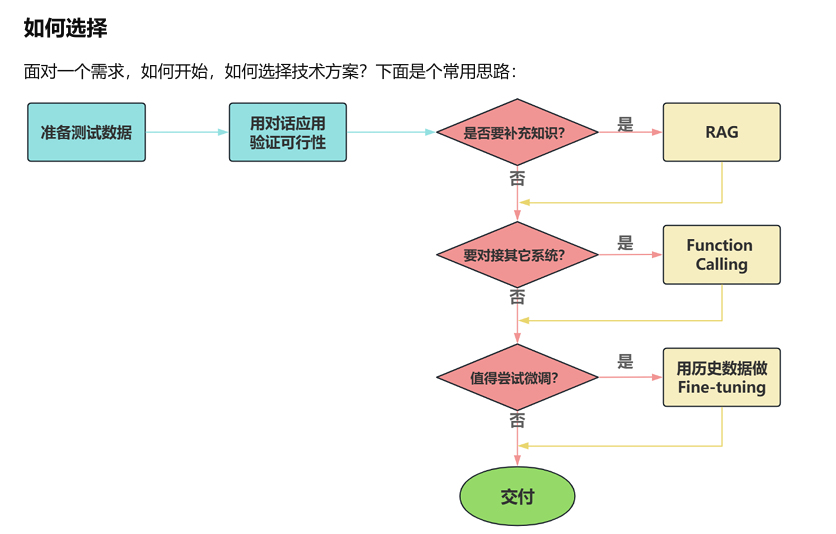
大模型应用开发的4个场景
场景1:纯 Prompt
Prompt是操作大模型的唯一接口
当人看:你说一句,ta回一句,你再说一句,ta再回一句…
场景2:Agent + Function Calling
Agent:AI 主动提要求
Function Calling:需要对接外部系统时,AI 要求执行某个函数
当人看:你问 ta「我明天去杭州出差,要带伞吗?」,ta 让你先看天气预报,你看了告诉ta,ta 再告诉你要不要带伞
场景3:RAG (Retrieval-Augmented Generation)
RAG:需要补充领域知识时使用
Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
向量数据库:把向量存起来,方便查找
向量搜索:根据输入向量,找到最相似的向量
场景4:Fine-tuning(精调/微调)
举例:努力学习考试内容,长期记住,活学活用。
铁塔项目利用大模型进行数据预处理:
| 处理前 | 处理后 |
|---|---|
 |
 |
5 总结与展望
本次属于一次技术交流,主要跟大家交流大模型应用开发的流程以及应用场景,目前大模型可以赋能在许多场景下。真正的潜力,在于我们将自身的业务理解与这些技术进行碰撞和结合。 目前在我们各个项目的实际工作中,都蕴藏着大量可以被AI优化的环节
同时大模型对传统前后端开发的岗位冲击很大,使得代码实现变得越来越容易,未来的开发者不再是纯粹的“码农”,而是要成为大模型的“指挥家”、AI应用的“架构师”、问题的“定义者”。所以我们非常有必要掌握一些大模型应用开发的知识,提升自己的个人竞争力,或者直接all in大模型应用开发岗。